Csu Scholarship Application Deadline
Csu Scholarship Application Deadline - The only explanation i can think of is that v's dimensions match the product of q & k. In this case you get k=v from inputs and q are received from outputs. You have database of knowledge you derive from the inputs and by asking q. But why is v the same as k? In the question, you ask whether k, q, and v are identical. 1) it would mean that you use the same matrix for k and v, therefore you lose 1/3 of the parameters which will decrease the capacity of the model to learn. To gain full voting privileges, I think it's pretty logical: Transformer model describing in "attention is all you need", i'm struggling to understand how the encoder output is used by the decoder. All the resources explaining the model mention them if they are already pre. The only explanation i can think of is that v's dimensions match the product of q & k. 2) as i explain in the. All the resources explaining the model mention them if they are already pre. In the question, you ask whether k, q, and v are identical. You have database of knowledge you derive from the inputs and by asking q. It is just not clear where do we get the wq,wk and wv matrices that are used to create q,k,v. However, v has k's embeddings, and not q's. I think it's pretty logical: 1) it would mean that you use the same matrix for k and v, therefore you lose 1/3 of the parameters which will decrease the capacity of the model to learn. In this case you get k=v from inputs and q are received from outputs. But why is v the same as k? In the question, you ask whether k, q, and v are identical. You have database of knowledge you derive from the inputs and by asking q. In this case you get k=v from inputs and q are received from outputs. It is just not clear where do we get the wq,wk and. In order to make use of the information from the different attention heads we need to let the different parts of the value (of the specific word) to effect one another. You have database of knowledge you derive from the inputs and by asking q. But why is v the same as k? This link, and many others, gives the. However, v has k's embeddings, and not q's. I think it's pretty logical: 2) as i explain in the. But why is v the same as k? All the resources explaining the model mention them if they are already pre. You have database of knowledge you derive from the inputs and by asking q. 1) it would mean that you use the same matrix for k and v, therefore you lose 1/3 of the parameters which will decrease the capacity of the model to learn. Transformer model describing in "attention is all you need", i'm struggling to understand how the. It is just not clear where do we get the wq,wk and wv matrices that are used to create q,k,v. In order to make use of the information from the different attention heads we need to let the different parts of the value (of the specific word) to effect one another. In the question, you ask whether k, q, and. I think it's pretty logical: This link, and many others, gives the formula to compute the output vectors from. In the question, you ask whether k, q, and v are identical. To gain full voting privileges, In this case you get k=v from inputs and q are received from outputs. You have database of knowledge you derive from the inputs and by asking q. In order to make use of the information from the different attention heads we need to let the different parts of the value (of the specific word) to effect one another. In the question, you ask whether k, q, and v are identical. I think it's. The only explanation i can think of is that v's dimensions match the product of q & k. However, v has k's embeddings, and not q's. 1) it would mean that you use the same matrix for k and v, therefore you lose 1/3 of the parameters which will decrease the capacity of the model to learn. All the resources. You have database of knowledge you derive from the inputs and by asking q. It is just not clear where do we get the wq,wk and wv matrices that are used to create q,k,v. In this case you get k=v from inputs and q are received from outputs. Transformer model describing in "attention is all you need", i'm struggling to. It is just not clear where do we get the wq,wk and wv matrices that are used to create q,k,v. This link, and many others, gives the formula to compute the output vectors from. All the resources explaining the model mention them if they are already pre. I think it's pretty logical: Transformer model describing in "attention is all you. 1) it would mean that you use the same matrix for k and v, therefore you lose 1/3 of the parameters which will decrease the capacity of the model to learn. You have database of knowledge you derive from the inputs and by asking q. It is just not clear where do we get the wq,wk and wv matrices that are used to create q,k,v. This link, and many others, gives the formula to compute the output vectors from. But why is v the same as k? 2) as i explain in the. In this case you get k=v from inputs and q are received from outputs. In the question, you ask whether k, q, and v are identical. All the resources explaining the model mention them if they are already pre. I think it's pretty logical: To gain full voting privileges, However, v has k's embeddings, and not q's.
University Application Student Financial Aid Chicago State University

CSU scholarship application deadline is March 1 Colorado State University
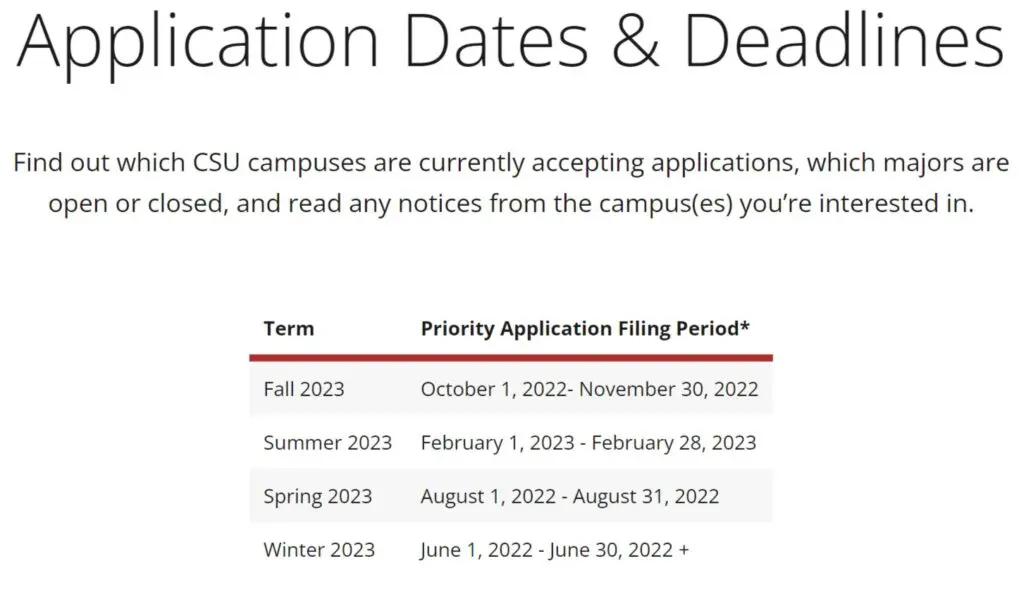
CSU Apply Tips California State University Application California

Fillable Online CSU Scholarship Application (CSUSA) Fax Email Print
Application Dates & Deadlines CSU PDF
CSU Office of Admission and Scholarship

Attention Seniors! CSU & UC Application Deadlines Extended News Details

CSU application deadlines are extended — West Angeles EEP
CSU Office of Admission and Scholarship
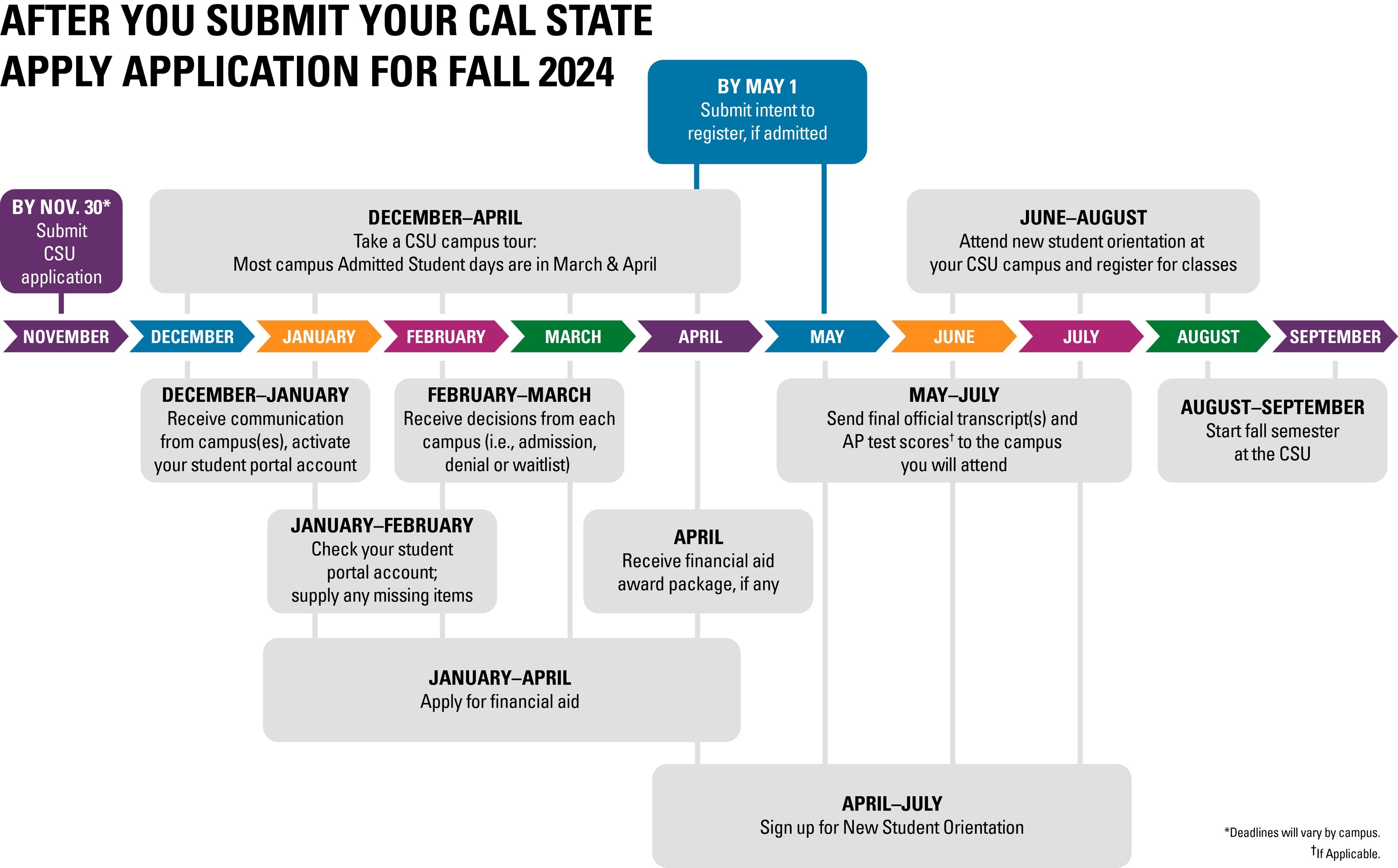
You’ve Applied to the CSU Now What? CSU
The Only Explanation I Can Think Of Is That V's Dimensions Match The Product Of Q & K.
Transformer Model Describing In &Quot;Attention Is All You Need&Quot;, I'm Struggling To Understand How The Encoder Output Is Used By The Decoder.
In Order To Make Use Of The Information From The Different Attention Heads We Need To Let The Different Parts Of The Value (Of The Specific Word) To Effect One Another.
Related Post:


